N-Tier Architecture Explained
In A Little Overview: Popular Software Architectures, I gave a quick overview of the three most popular and commonly used software architectures. With this brief glance, I tried to create a little window for you to peek through and see what some architectures look like from the inside. Let’s open the first door of the many houses we’ll visit and start with the n-tier architecture.
Reason for popularity
This architecture is by far one of the most popular. Architects introduced this pattern in the ‘90s; it has dominated the market ever since. It targeted the monolithic applications, and it gained popularity when the internet arrived. It created scalability for web applications using one input channel, a browser.
It also happens to be one of the easiest to learn as well. The concepts are quite simple, thus easy to understand the core basics and mechanics of this architecture. Hence it is often the first architecture students software engineering are learning these days. This further increases the popularity of this pattern because many software engineers and programmers are already familiar with this architecture.
Do not be fooled, though; the layered architecture pattern can be hard to implement! It depends greatly on the complexity of your application. But let’s not get ahead of ourselves yet and let’s recap the concepts of the n-tier architecture and add a few minor ones as well.
The Concept
As stated in the previous post about popular architectures, the n-tier architecture uses the concept of layers to divide software functionality. Each layer has one purpose only which makes the code better readable as well. A class won’t be a mix of database code, business logic and presentation code; it will only contain either database code, either business logic, either presentation code. So, if you’re looking for the business logic of a particular object, you only have to go to the business layer and search for your specific object.
Aside from making the code more readable, dividing the code as another purpose. Each layer is independent and closed. It does not require the layer above or below to function properly. However, the tiers need each other to pass information. This also means that each layer of the software can be tested independently. By mocking the layers around the one you want to test, you can test the full functionality of a layer.
Furthermore, because each layer is independent, they are also isolated. If only the business logic needs a change, then developers apply this change. The change will not affect the surrounding layers. Having the tiers isolated, makes it easier to apply changes to the software and add new features.
N-Tier Architecture in Practise
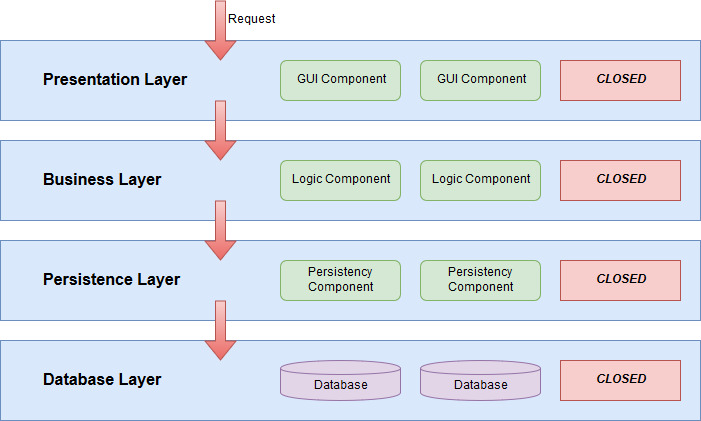
So, what would this architecture look like within an application and how does it work? Let’s go through that with John. John is creating a simple website that handles books. He created an Angular frontend, this is his presentation layer. He also created a Java backend, containing the other layers. These layers are the business layer and persistence layer. He also has a database to store all the books.
The picture above gives a good representation of how Johns software is structured. He goes to his website to test the functionalities. He pressed a button labelled “Get All Books”. The presentation layer wants data from the database. However, all the layers are closed so the presentation tier cannot go to the database directly. Thus, the presentation layer asks the business layer for all the books. As long as the presentation layer acquires the information it needs, it is as happy as a dog.
Now, the business layer got a request from the presentation layer for information on all the books. Again, because all the layers are closed, even the business tier cannot access the database directly. However, it does have a communication line with the persistence layer. Hence the business layer asks the persistence layer for the data. This tier goes to the database and requests for information on all the books. Once it has a response from the database, it sends the data back to the business layer. Now, a website cannot do much with a whole lot of data on books. It actually only needs the title of the book and its author. Thus, the business layer makes sure to alter the data as such that it sends back only the data the presentation layer needs. This data is then displayed on Johns website.
Open Layers
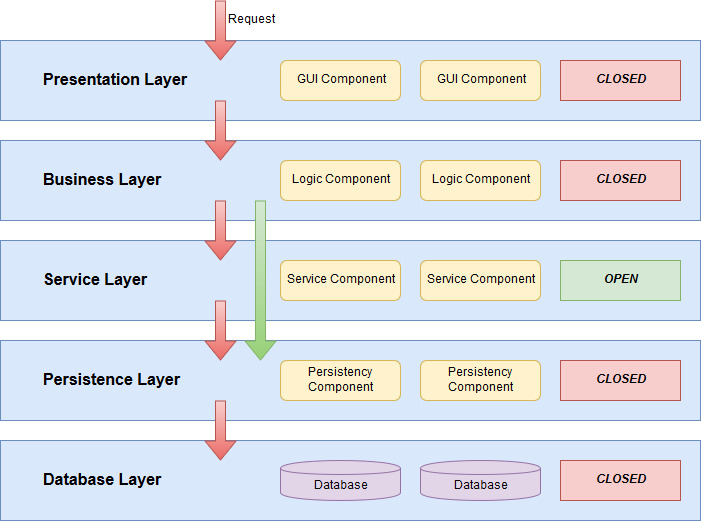
Sometimes, an extra step is needed for a component to complete a calculation. And sometimes, this extra step is implemented by multiple components with little to no differences between the implementations. Therefore, developers separate these steps or calculations into smaller services that can be used by the components.
If we applied this concept in the n-tier architecture, we would end up with a service layer. This layer contains all the small services that are used by the business layer and all its components. This also means that the service layer itself is isolated, just like the others.
A service layer, like said, only contains small pieces of code which business layer components use for their calculations. It only exists to aid the business layer. Therefore, this tier is not part of the dataflow chain. However, all the layers are closed. Thus every request has to pass through the service layer in order to get to the persistence layer. This is, of course, not useful at all. Hence, the n-tier architecture can also contain open layers. These layers can be skipped to reach the layer beneath. These open layers still have connections to the layer below them, because a service should be able to make use of a database. We can see this in the following image:
Monolithic
During the time it was introduced, the n-tier architecture provided a way to scale the old fashioned monolithic applications. However, by today’s standards, this pattern is regarded monolithic as well. This architecture is designed to support one user input channel like a browser. These days, people expect to have multiple ways to access a service. Think about iOS or Android apps, web browsers, APIs, and many other ways to acquire the information.
Another aspect of today’s software development is the speed of each release. Especially with Agile being implemented in many software companies, companies are having more frequent releases: about every week to every month. This architecture is not designed to adapt to this frequency. With this pattern, the whole application has to be deployed at once. As opposed to microservices, you cannot deploy a specific layer to make the new functionality available. Hence deploying software with this architecture can be time-consuming which explains why it doesn’t happen that often.